Liberating Results PDFs with Tabula
By Derek Willis
As much as we'd love to be able to report that election agencies only deliver results in structured data files, that's not the case. In many states we're fortunate to find electronically-generated PDFs, which at least contain the promise of data if not always the ease of access.
Take New Mexico, for example. The Secretary of State's office provides precinct-level results files for each county, including absentee ballots. But the files are PDFs, and there's another catch: although the results are typical rows and columns as you might find in a spreadsheet, the column headers listing the candidate names are vertically aligned, like so:
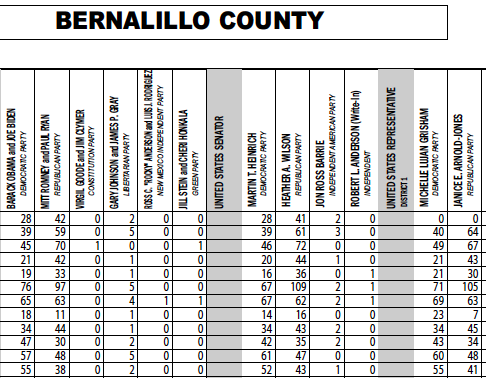
That causes some issues when either copying and pasting directly from the PDF or when using a utility such as xPDF, which converts electronic PDFs into text files while attempting to preserve the layout. The vertical alignment issue will require a certain amount of manual intervention, but the question is: how much?
We've been looking at Tabula, an open-source project created by Manuel Aristarán with the support of ProPublica, La Nación DATA and Knight-Mozilla OpenNews. It helps extract structured data from PDFs, but allows some user control over the process. Tabula users draw a box around the area of the PDF they want to extract, and then can copy the table as a CSV or tab-delimited text file.
When I learned about the PDF Liberation Hackathon being held in several cities in January, I gently asked on Twitter what might be possible with a New Mexico results file. Turns out, quite a lot.
Jeremy Merrill, one of Tabula's developers, responded that Tabula could extract the data, but had the same issue with the vertical headers. Unlike other text extraction utilities, however, Tabula could work around the headers, because it allows you to select an area of the PDF that you want to extract. So I took that route, drawing a box over just the data from the presidential race.
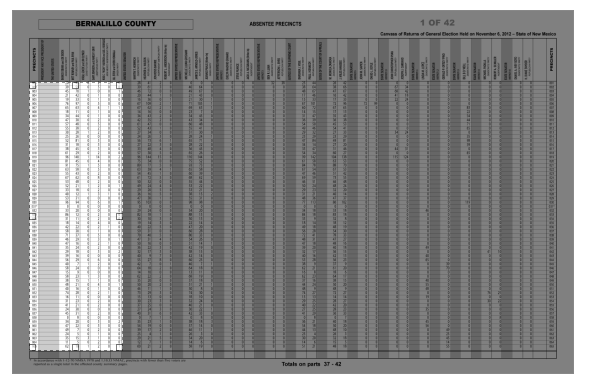
The results are impressive, and Tabula makes it easy to grab or download the data:
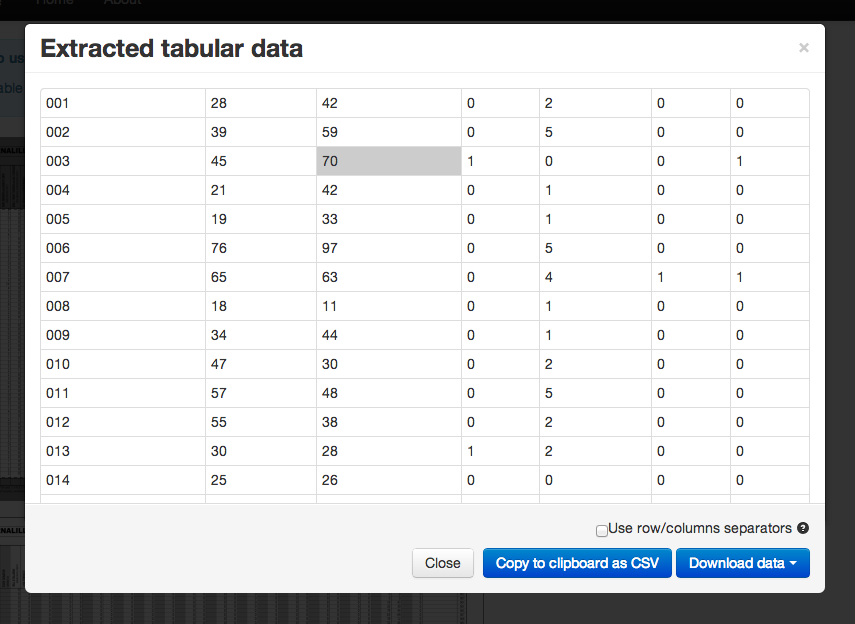
Some issues remain - the empty columns in the PDF seem to cause Tabula some issues, so extracting all of the data on each page could require drawing multiple boxes. But that's still better than trying to clean up problematic text dumped out randomly with the data columns interspersed. Tabula may be especially useful with results files at the local level, which often are published as PDFs.
As we work with the data from more states, we're finding that many will have their own challenges. As a result, we're not only going to extract the data that we need, we're also adding a state-specific file to our main repository that will explain the steps we took to retrieve and process the results. That will include listing any software we used, so that people who want to replicate or check our processes can retrace our steps as closely as possible.
Some states that use PDFs will be easier to work with, while others will be much harder. It's nice to know that there are open source tools that are getting more sophisticated and useful, and that we can make them a part of our effort.